What is CometCloud Workflow?¶
Summary¶
CometCloud Workflow is a framework that enables scientists with mechanisms that ease the autonomic execution of complex workflows in software-defined multi-cloud environments. This framework is built on top of CometCloud and its federation model, which enables the dynamic creation of federated “Cloud-of-Clouds”. The resulting solution is a platform that takes a workflow description from the user and autonomously orchestrates the execution of such a workflow by elastically composing appropriate cloud services and capabilities to ensure that the user’s objectives are met.
The design of our framework defines three main management units: Workflow management, which takes application information from the user, identifies dependencies, and controls the execution of the workflow. Autonomic management, which acts as the “brain” of our architecture by storing and analysing all data collected from applications and resources, which is used to take operational decisions adapting allocated resources to meet user’s objectives.Federation management, which uses software-defined techniques to create an elastic and dynamic federation of resources that can shape itself based on user’s constraints or resources availability. Figure 1 shows a general overview of this model, where each federation site sees the rest of sites as a pool of elastic resources.
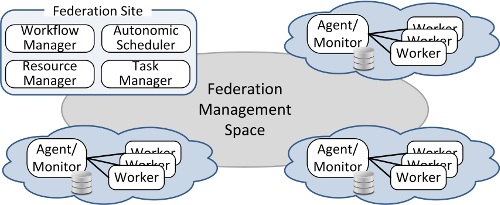
Figure 1: Federation Architecture
In the model, users at every site have access to a set of heterogeneous and dynamic resources, such as public/private clouds, supercomputers, and grids. These resources are uniformly exposed using cloud-like abstractions and mechanisms that facilitate the execution of applications across the resources. The federation is dynamically created in a collaborative way, where sites “talk” to each other to identify themselves, negotiate the terms of adhesion, discover available resources, and advertise their own resources and capabilities. Sites can join and leave at any point. Notably, this requires a minimal configuration at each site that amounts to specifying the available resources, a queuing system or a type of cloud, and credentials. As a part of the adhesion negotiation, sites may have to verify their identities using security mechanisms such as X.509 certificates, or public/private key authentication.
Realizing Scientific Workflows¶
We envision a scenario in which popular applications contributed by the scientific community are deployed within the federation such that they can be accessed on-demand and at the same time benefit from the distributed resources. With applications pre-deployed in the federation, scientists would be only required to define a high-level workflow description. Figure 2 depicts the end-to-end process involved in the execution of a workflow.
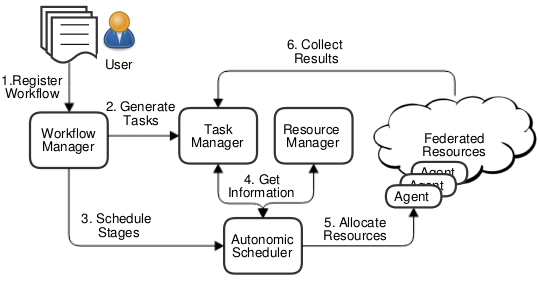
Figure 2: Workflow Execution Process
The main actor is the actual user, who is required to describe his/her workflow. The description of a workflow is an XML document that collects the properties of the comprising stages. Each stage defines the application to use; location of the input and output data; dependencies with other stages; and the scheduling policy that will drive the execution. The user initiates the execution of the workflow by registering its description in the Workflow Manager. This operation returns an identifier to the user, which can be next used to perform operations such as checking the status of the workflow, or retrieving results. Using the workflow description, the workflow manager can autonomously proceed with the execution. First, it identifies dependencies across stages and selects those stages that are ready to execute, i.e., all their dependencies are satisfied. Then, the description of these stages is sent to the Task Manager that generates and keeps track of all tasks composing the stages executed at a given site. The task generation process depends on the type of application and the logic associated with it. Once all tasks are generated, the workflow manager is notified and it passes control to the autonomic scheduler which allocates resources for these tasks.
Scheduling tasks of a stage involves the autonomic scheduler performing four steps: (i) retrieving the information of the available resources from the Resource Manager (i.e., resource availability, relative performance, cost); (ii) retrieving information related to the tasks to execute (i.e., data location and task complexity); (iii) identifying the scheduling policy selected by the user; and (iv) using that scheduling policy to decide which resources to provision, from which site, for how long, and where to execute each task.
Once the scheduling decision is made, the autonomic scheduler dynamically allocates the required resources from each site. Resources at each site are offered to the rest of the federation through a common interface. This interface is implemented by an Agent that acts as a gateway. Therefore, the autonomic scheduler has to interact with the appropriate agents to provision/allocate resources. Agents know the status of their resources and how to interact with them. For example, an agent may provision virtual machines (VMs) when working with a cloud or reserve machines using a queuing system when interacting with an HPC cluster. In case of failure, the autonomic scheduler is notified so that it can take appropriate actions. In case of success, a worker is deployed in each machine/VM to immediately start retrieving and executing tasks. Any required input data is automatically transferred upon request.
Task results are collected by the task manager. This component keeps the autonomic scheduler informed about the progress to allow changes in the schedule at runtime and deallocate/terminate resources when they are not needed. When all the tasks of a stage are completed, the workflow manager is notified to identify new stages ready to be executed. This process continues until all stages are completed.
A Metrics Service can be enabled to store data from the Agents regarding resource performance for different applications, failure rates, provisioning overheads, network performance between Agents and between an Agent and its workers. In this way the autonomic scheduler can learn from past experience to improve estimations.